Avant de déployer votre API dans le monde sauvage du web, assurez-vous de passer en revue cette check-list essentielle pour la sécurité :
https://img.freepik.com/
1️⃣ Authentification & Autorisation : Mettez en place des tokens robustes (comme JWT ou OAuth). Implémentez des contrôles d’accès basés sur les rôles (RBAC).
2️⃣ Validation & Sanitisation des Entrées : Établissez des règles strictes de validation des entrées. Sanitisez toutes les données reçues.
3️⃣ Gestion des Erreurs & Journalisation : Utilisez des messages d’erreur génériques. Mettez en place une politique de journalisation cohérente.
4️⃣ Chiffrement : Activez HTTPS pour toutes les communications. Chiffrez les données sensibles côté serveur.
5️⃣ Rate Limiting et Throttling : Limitez le nombre de requêtes acceptées dans un temps donné.
6️⃣ Minimisation des Endpoints : Exposez uniquement les endpoints absolument nécessaires.
7️⃣ Sécurisation de la Documentation : Gardez votre documentation de l’API sécurisée et non publique.
8️⃣ Mises à Jour de Sécurité : Gardez toutes vos dépendances à jour.
9️⃣ Tests de Sécurité : Planifiez des tests de pénétration et des analyses de sécurité régulières.
🔟 Headers HTTP de Sécurité & Gestion des Sessions : Utilisez des en-têtes de sécurité HTTP appropriés. Implémentez une gestion rigoureuse des sessions avec des tokens à durée de vie limitée.
💡 N’oubliez pas : La sécurité de votre API est aussi importante que ses fonctionnalités. Un seul point faible peut mettre en péril non seulement votre application mais aussi les données sensibles de vos utilisateurs. Prenez le temps de faire les choses correctement !
La technologie est un domaine en constante évolution, et pour rester informé, j’ai pris l’habitude d’écouter des podcasts. Aujourd’hui, je souhaite partager avec vous deux d’entre eux qui m’ont particulièrement marqué.
Le Board: Pour les Solopreneurs et Plus Encore
Le Board est initialement conçu pour les solopreneurs, ces entrepreneurs qui travaillent seuls. Pourtant, j’ai trouvé que les sujets abordés touchaient un public bien plus large. Le podcast offre de nombreux conseils, en particulier sur la gestion du temps, qui peuvent s’avérer utiles pour tout professionnel.
Artisan Développeur: Un Regard sur le Développement de Qualité
Artisan Développeur est une source d’inspiration pour les développeurs qui cherchent à améliorer leurs compétences. Il traite des méthodes de développement, comme le TDD, mais aussi de comment instaurer ces bonnes pratiques au sein d’une équipe.
La Valeur des Invités
La variété des intervenants est un atout majeur de ces podcasts. Chaque épisode propose des perspectives différentes, offrant une vue d’ensemble enrichissante sur le monde de la tech freelance en France.
Pour Conclure
J’ai trouvé ces podcasts à la fois informatifs et accessibles. Que vous soyez dans le domaine de la tech ou simplement curieux, je vous recommande de leur donner une chance. Ils offrent des insights précieux dans un format agréable à écouter.
L’utilisation de l’intelligence artificielle (IA) dans le développement de logiciels est devenue presque incontournable. Dans cet article, je vais partager une expérience sur l’utilisation de l’IA pour accéder à des bases de données médicamenteuses en français.
Les avantages de l’IA dans le Développement
L’IA peut grandement accélérer le processus de développement en automatisant des tâches répétitives comme la recherche de documentation ou l’analyse de code. Par exemple, en donnant un exemple de classe, l’IA va pouvoir vous générer un template utilisable de fichier de test, elle pourra également vous montrer comment générer rapidement un ensemble de données « vraisemblable ». S’en passer serait prendre un risque important de perte d’efficacité.
Les limitations de l’IA
Cependant, il est important de noter que chaque IA a ses limitations. Dans le cas, suivant, on voit les manques de ChatGPT du, sans doute, à une actualisation des données depuis la création de ses données d’apprentissage. Sur le cas suivant, la différence de réponse va soit vous permettre d’accélérer votre travail, soit vous menez dans une solution impossible à réaliser dans un temps raisonnable.
J’ai récemment eu besoin d’accéder à une base de données médicamenteuse en français. J’ai d’abord consulté ChatGPT, qui m’a orienté vers la Base de données publique des médicaments du gouvernement français. Cependant, cette base de données ne propose pas d’API publique, ce qui limite son utilisation dans un contexte de développement. La solution proposée par chatGpt était soit de scraper le site, soit de me tourner vers des solutions concurrentes (non officiel) ou sur des données de recherche.
En revanche, la solution proposée par Bard (Google) était plus complète, offrant non seulement des informations sur la base de données mais aussi des alternatives pour y accéder. En effet, si ce site ne propose pas directement une api pour consulter ses données, il propose un téléchargement d’une série de fichier décrivant l’ensemble des médicaments . Si ce n’est une API, cela reste une méthode efficace pour avoir accès aux données souhaitées.
En conclusion,
Se fier à une unique source de données, quelles qu’elle soit, IA ou non, est une erreur. L’IA peut être un outil puissant pour les développeurs, mais il est crucial de comprendre ses avantages et ses limitations. Il faut tester et toujours mettre en doute une solution qui ne vous parait pas la plus simple.
L’intelligence artificielle (IA) est en pleine effervescence, et le monde des chatbots n’est pas en reste. Au cœur de cette révolution se trouve ChatGPT d’OpenAI, une technologie qui se démarque par sa capacité à évoluer et à s’adapter grâce aux plugins. Si vous êtes un développeur en quête d’un projet passionnant, voici pourquoi vous devriez envisager de plonger dans l’écosystème des plugins ChatGPT.
Sous le capot : L’architecture des plugins ChatGPT
Un plugin pour ChatGPT n’est pas simplement un add-on. C’est un module d’extension puissant qui peut transformer, améliorer ou diversifier les capacités intrinsèques du modèle. Ces extensions sont méticuleusement conçues pour s’harmoniser avec l’API de ChatGPT, garantissant une fusion transparente sans sacrifier les performances du modèle.
Pourquoi les plugins sont-ils le futur de ChatGPT ?
Modularité: Ils offrent une architecture propre, assurant que le cœur de ChatGPT demeure solide tout en évoluant.
Scalabilité: Grâce à leur conception, l’intégration de nouvelles fonctionnalités est fluide, sans impact négatif sur le système global.
Interopérabilité: Avec des interfaces bien définies, les plugins peuvent facilement dialoguer avec d’autres systèmes et bases de données, élargissant ainsi le champ des possibles.
Monétisation: Pour les esprits entrepreneuriaux, les plugins peuvent être transformés en produits premium, ouvrant la voie à des opportunités financières.
AI nuclear energy, future innovation of disruptive technology
Les avantages d’un side project axé sur ChatGPT :
Montée en compétence: C’est une chance inouïe de perfectionner vos compétences en programmation, NLP et IA.
Opportunités financières: Un plugin innovant peut non seulement répondre à un besoin, mais aussi devenir une source de revenus.
Visibilité: Enrichir l’écosystème ChatGPT peut vous positionner comme un acteur clé au sein de la communauté tech et IA.
Liberté créative: Sans les contraintes d’un environnement professionnel formel, vous pouvez expérimenter, innover et peaufiner à votre rythme.
Réponse à un besoin: Si ChatGPT manque d’une fonctionnalité que vous désirez, pourquoi ne pas la créer vous-même ?
Acquisition de compétences diverses: Gérer un projet de A à Z vous permet d’acquérir des compétences en gestion, marketing et communication.
En bref,
Se lancer dans la création d’un plugin pour ChatGPT est bien plus qu’un simple side project. C’est une aventure enrichissante, une opportunité d’apprentissage et un tremplin vers de nouvelles opportunités. Pour les passionnés de technologie, c’est le moment idéal pour contribuer et façonner l’avenir des chatbots.
La sécurisation des données dans les applications médicales est le point essentiel. Il vous faut toujours savoir qui, à quoi et quand une donnée est accédé. Cette donnée est sensible et soumise à une réglementation stricte. La blockchain est lune technologie qui permet de stocker et de vérifier de manière sécurisée les transactions et les données. Son adoption dans les applications médicales offre plusieurs avantages pour le secteur de la santé.
Pourquoi son adoption (ou pas) ?
La blockchain permet d’améliorer la sécurité des données médicales. Les informations médicales sont sensibles et doivent être protégées contre les accès non autorisés. La blockchain utilise des algorithmes cryptographiques avancés pour garantir l’intégrité et la confidentialité des données médicales, ce qui réduit le risque de falsification ou de violation de la vie privée. Cette technologie facilite la traçabilité et l’authenticité des données médicales. Dans le domaine de la santé, il est essentiel de pouvoir suivre l’origine et l’historique des données médicales, telles que les résultats des tests, les dossiers médicaux et les prescriptions. Grâce à la blockchain, chaque transaction est enregistrée de manière transparente et immuable, ce qui permet de vérifier l’authenticité des données et de retracer leur parcours.
La blockchain est également une technologie qui favorise l’interopérabilité des systèmes de santé. Les applications médicales peuvent utiliser la blockchain comme un protocole standard pour échanger des données médicales entre différentes plateformes et institutions. Cela facilite la collaboration et le partage d’informations entre les différents acteurs du secteur de la santé, tels que les hôpitaux, les médecins et les laboratoires.
Enfin, la blockchain offre des opportunités pour améliorer la gestion des identités dans les applications médicales. Grâce à la blockchain, il est possible de créer des identités numériques uniques et vérifiables pour les patients, les médecins et d’autres acteurs du domaine médical. Cela simplifie les processus d’identification, de vérification et d’autorisation, tout en préservant la confidentialité des données personnelles.
Les défis ?
L’adoption de la blockchain dans les applications médicales présente également des défis. Parmi ceux-ci, on retrouve la mise à l’échelle de la blockchain pour gérer un grand volume de transactions, la compatibilité avec les réglementations en matière de protection des données, et les coûts associés à la mise en place et à la maintenance d’une infrastructure blockchain.
Pour quelles types d’applications ?
Gestion des dossiers médicaux électroniques : La blockchain peut être utilisée pour créer un système sécurisé de gestion des dossiers médicaux électroniques. Les dossiers médicaux pourraient être stockés sur la blockchain, ce qui permettrait aux patients et aux professionnels de la santé d’accéder aux informations médicales de manière sécurisée et transparente, tout en préservant la confidentialité.
Suivi de la chaîne d’approvisionnement pharmaceutique : La blockchain peut être utilisée pour suivre le cheminement des médicaments depuis leur fabrication jusqu’à leur utilisation par les patients. Cela permet de garantir l’authenticité des médicaments, de lutter contre la contrefaçon et de surveiller les conditions de stockage pour assurer la qualité des produits pharmaceutiques.
Partage sécurisé des données de recherche médicale : La blockchain peut faciliter le partage sécurisé des données de recherche médicale entre différentes institutions et chercheurs. Les données pourraient être stockées de manière décentralisée sur la blockchain, garantissant ainsi la transparence, l’intégrité et la traçabilité des informations, tout en préservant la confidentialité des patients.
Gestion des consentements et autorisations : La blockchain peut être utilisée pour gérer les consentements et les autorisations des patients concernant l’accès à leurs données médicales. Les patients pourraient utiliser des identités numériques vérifiables sur la blockchain pour contrôler et donner leur consentement à différentes entités pour accéder à leurs informations médicales.
Systèmes d’assurance santé basés sur la blockchain : La blockchain peut être utilisée pour créer des systèmes d’assurance santé décentralisés et transparents. Les contrats d’assurance et les paiements pourraient être automatisés en utilisant des contrats intelligents sur la blockchain, réduisant ainsi les coûts administratifs et les risques de fraude.
Une technologie en vogue ou réelle ?
C’est aujourd’hui une technologie qui a dépassé le cadre de l’innovation. De nombreuses preuves de concept ont été réalisées … mais peut-on réellement parler d’une technologie accessible tel une brique classique.
Voici quelques pokes reconnu :
MedRec (2017) est un projet de recherche développé par le Massachusetts Institute of Technology (MIT) qui utilise la blockchain pour la gestion sécurisée des dossiers médicaux électroniques. Il permet aux patients de contrôler l’accès à leurs données médicales et de partager des informations spécifiques avec des professionnels de la santé. Ce projet datant de 2017 (https://www.media.mit.edu/publications/medrec-blockchain-for-medical-data-access-permission-management-and-trend-analysis/) expose comment il est possible de partager une information sensible en se basant sur une blockchain connue : l’Etherum.
SimplyVital Health utilise la blockchain pour développer des solutions de suivi et de partage des données de santé pour les fournisseurs de soins de santé et les patients. Leur plateforme, appelée Health Nexus, permet de stocker les dossiers médicaux, de suivre les résultats des traitements et de faciliter les remboursements d’assurance.
Lancé en 2017 et après plusieurs levée de fond importante, le projet semble inactif depuis 2021 …
Medicalchain est une plateforme basée sur la blockchain qui vise à sécuriser et à faciliter le partage des données médicales. Elle permet aux patients d’accéder à leurs dossiers médicaux, de donner leur consentement pour le partage des informations et de consulter des médecins en ligne en toute confidentialité.
Le projet semble toujours actif mais la roadmap affichée en ligne s’arrête en 2019 … Ce n’est pas bon signe …
En résumé
La technologie semble intéressante sur le papier mais pour le moment son adoption est lente. Ce qui est sur c’est que de depuis 2017, la date du papier pour le projet Medrec, la technologie blockchain n’est pas devenue un élément incontournable de la sécurisation du développement des applications médicales. Le terme blockchain ne fait pas encore part des mots clés des offres d’emploi dans le domaine des applications médicales.
Est-ce qu’il faut continuer à s’informer sur ces technologies ? Je pense que oui. Le domaine de la donnée médicale est encore trop peu sécurisé. L’échange de données non protégées est encore trop fréquent sous couvert qu’il s’agit de données anonymisées.
Manipuler des données avec Python, c’est rapide. Fournir un fichier Excel, c’est également possible, mais souvent insuffisant pour une diffusion sous forme de livrable.
Un résultat sous forme de Word est possible.
Le point de départ, c’est le dataframe. Il s’agit de l’objet produit par Pandas et permettant de manipuler facilement et rapidement vos données.
voici un exemple rapide permettant de créer un tableau de manière dynamique.
import pandas as pd
from docx import Document
# Créer un DataFrame de test
data = {'Nom': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'Ville': ['Paris', 'Londres', 'New York']}
df = pd.DataFrame(data)
# Créer un nouveau document
document = Document()
# Ajouter un titre
document.add_heading('Tableau de test', 0)
# Ajouter un tableau à partir du DataFrame
table = document.add_table(rows=1, cols=len(df.columns))
hdr_cells = table.rows[0].cells
for i, colname in enumerate(df.columns):
hdr_cells[i].text = colname
for i in range(len(df)):
row_cells = table.add_row().cells
for j, val in enumerate(df.iloc[i]):
row_cells[j].text = str(val)
# Enregistrer le document
document.save('test_table_df.docx')
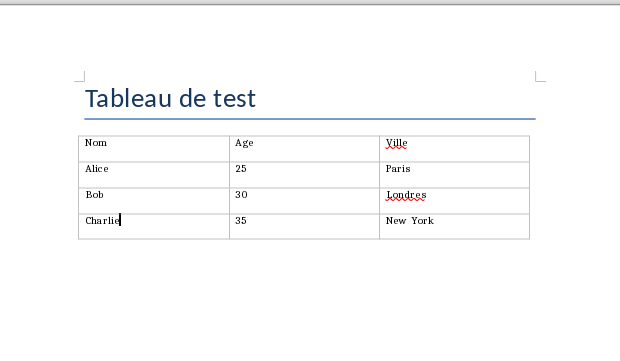
Et vous arrivez rapidement à ce résultat :
Par la suite, il suffit d’intégrer ces routines dans la gestion de vos templates Word … et vous pouvez produire directement un livrable final à votre équipe. (et pas un fichier devant être manipuler avant de pouvoir être diffuser.
En tant que développeur, il est rare que nos algorithmes soient vraiment révolutionnaires. Souvent nos travaux sont tout autre. Nous devons assembler, comprendre le métier, proposer des solutions innovantes .. mais pas faire des algorithmes réellement complexes. La difficulté est réelle .. mais il ne s’agit pas d’algorithme à proprement dit.
Les challenges de programmation sont une occasion unique de faire travailler nos méninges, bien fatigué par des années de temps perdu à comprendre pourquoi « le ca marche sur mon PC » ne s’applique plus en production.
Les challenges peuvent être plus ou moins long et plus ou moins sponsorisés. Votre objectifs sera soit de vous faire remarquer par un recruteur … soit simplement prendre du plaisir.
Durant les fêtes qui s’approche, le site Coding Game propose un concours particulier par sa longueur. Vous aurez 3 semaines pour réfléchir, aucune excuse pour ne pas s’y frotter.
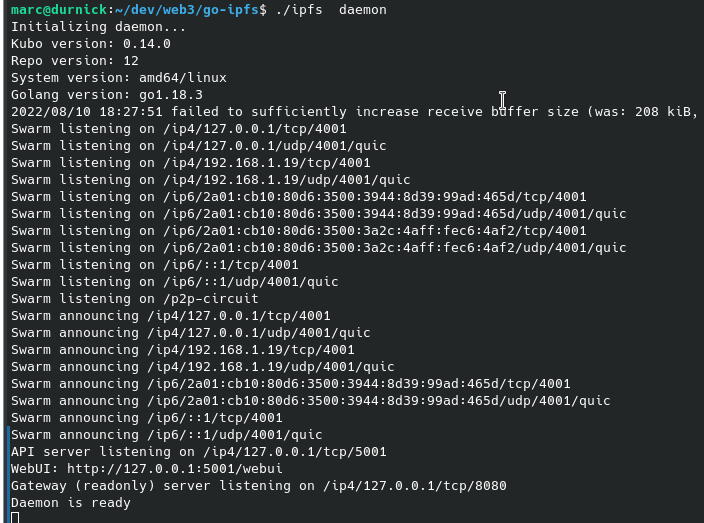
Le nœud est ensuite opérationnel et consultable sur l’url local suivante :
L’ajout d’un fichier à l’aide de la ligne de commande se fait via : ./ipfs add ../merle.jpg
Cette commande vous affichera le hash correspondant à votre fichier :
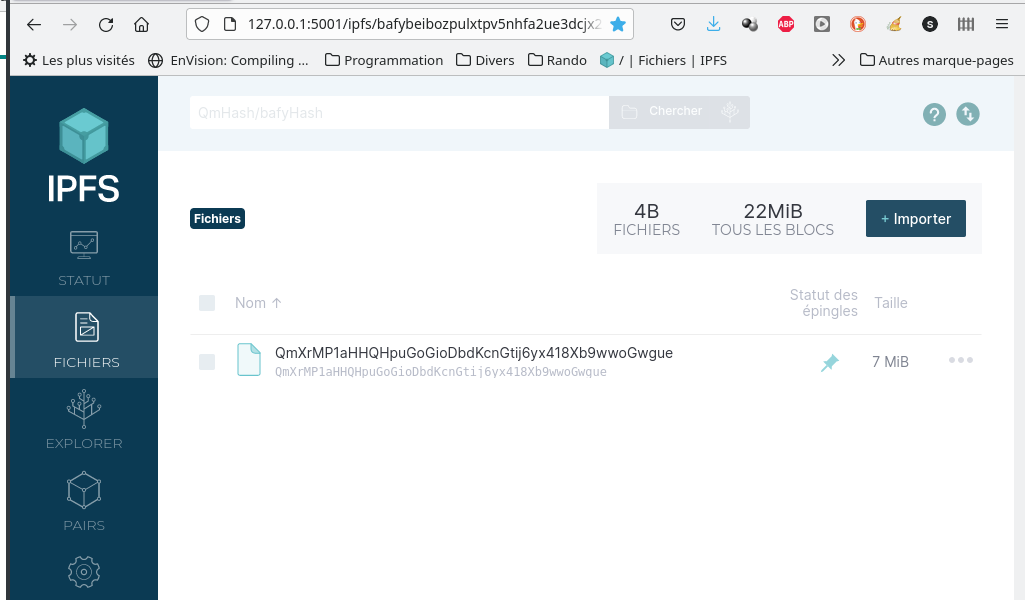
Cette valeur ( QmXrMP1aHHQHpuGoGioDbdKcnGtij6yx418Xb9wwoGwgue ) correspond à l’identifiant unique de votre fichier. Il peut ensuite être utilisé pour localiser ou faire des actions dessus.
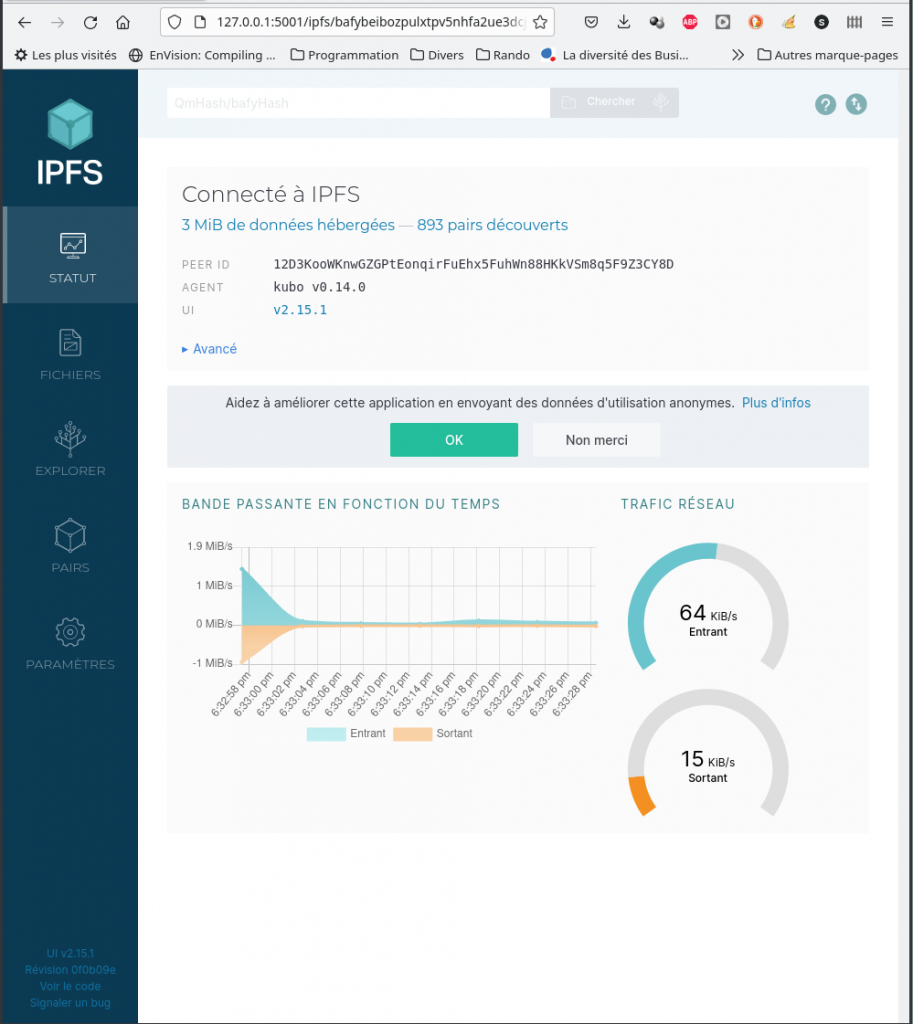
Depuis l’interface Web, il est possible de vérifier l’enregistrement de votre fichier :
Toutes les actions faisables en ligne sont réalisables depuis la console. La suppression via rm, l’étiquetage, via pin add pour l’étiquetage de fichier.
La mise en place de ce type de service est ultra-basique. Il est recommandé d’utiliser un service d’étiquetage centralisé pour faciliter la diffusion de ses fichiers. Une fois ceci fait, on peut se lancer dans d’autres expériences : la publication d’un site web statique directement en IPFS, l’hébergement d’une collection de NTF.
L’objectif est de pouvoir proposer de manière simple ces fichiers au plus grand nombre sans risque de défaillance d’un serveur centralisé.
Nota : cet article est assez court mais a pour objectif d’être le premier dans ma découverte du web3. A suivre donc ^^
Dans l’article précédent, nous étions partis sur une extraction des données. En effet, notre objectif était d’avoir une résultat rapide afin d’avoir des données affichages. Nous sommes donc sur un cas d’école entre le cas utilisé par un développeur qui travail sur une extraction afin de valider ses travaux … qui échoue une fois les données de production utilisées.
En regardant le volume des données, rien de plus normal. Nous utilisons comme base de travail 3 fichiers de plusieurs gigas que nous combinons entre eux avant de faire les opérations. Autant dire que cela explose très rapidement.
En ré-ordonnant les opérations, et filtrant les données, tout rentre dans l’ordre.
#calcul de la rémunération (avantage) data = data_avantages.groupby([« entreprise_identifiant »])[« avant_montant_ttc »].sum().sort_values(ascending=False).head(nb_entreprise)
L’objectif de cet article est donc de montrer une chaîne complète de traitement de l’information, permettant à partir d’un ensemble de fichier résultat de type CSV, d’aller à un tableau formaté, pouvant être directement diffusé.
Le choix des données initiales
Pour avoir une base de travail, le plus simple est de partir sur des données issues de l’Open Data. Ces données sont facilement accessibles, fournies dans un résultat exploitable .. et sont souvent des mines d’information.
Mon choix c’est fait sur la base de données Transparence. Ces données sont directement accessible sur le portail suivant : transparence-santé.
La modélisation des données est la suivante :
Un fichier pour la description des entreprises
Un fichier pour la description des avantages
Un fichier pour la description des conventions.
La manipulation des données en Python
Nous allons faire simple, car dans ce cas précis, l’objectif est de voir comment charger les données, renseigner les jointures entre elles et produire quelques résultats.
Les données sont actuellement centrées sur l’entreprise. Notre exemple sera de construire un graphique contenant les 50 entreprises les plus dépensières (convention + avantage).
Chargement et jointure des fichiers
Pour le chargement des fichiers, le plus simple est d’utiliser les méthodes mises à disposition par le frameworks Panda. Mais avant tout chose, il est nécessaire de se faire un jeu de données possédant une taille utilisable pour les tests.
Le plus simple est de prendre une sous-sélection des fichiers de bases. Avec un environnement bash, la commande head permet de faire cela très rapidement.
head -n 50 avantage.csv > avantage_light.csv
Une bonne habitude est d’utiliser dès que possible un fichier de configuration pour votre projet. Les chaînes magiques ont malheureusement tendance à rester beaucoup trop longtemps dans les projets
Les travaux préparatoires sont maintenant terminés
Après une rapide analyse des fichiers, tous utilisent l’identifiant de l’entreprise comme données de jointure. Le seul point à prendre en compte porte sur le fait que suivant le fichier, l’identifiant n’a pas le même nom. Il faut donc préciser le nom de la colonne pour pouvoir faire un rapprochement.
La jointure se fait donc à l’aide de la commande suivante :
Puis, afin de regrouper les données par secteurs, il faut faire une opération de regroupement sur deux informations : le secteur et le nom de l’entreprise :
(La commande finale head(50) permet de limiter l’extraction au 50 premières lignes, utile en cas de test)
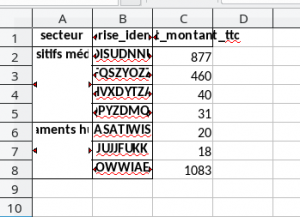
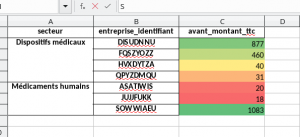
data = data_merge.groupby(["secteur","entreprise_identifiant"])["avant_montant_ttc"].sum().head(50)
L’enregistrement basic dans un fichier excel se fait avec la commande suivante :
data.to_excel(writer, sheet_name="Avantage")
Simple, mais peu exploitable en production. En effet, le résultat obtenu n’est pas des plus présentable.