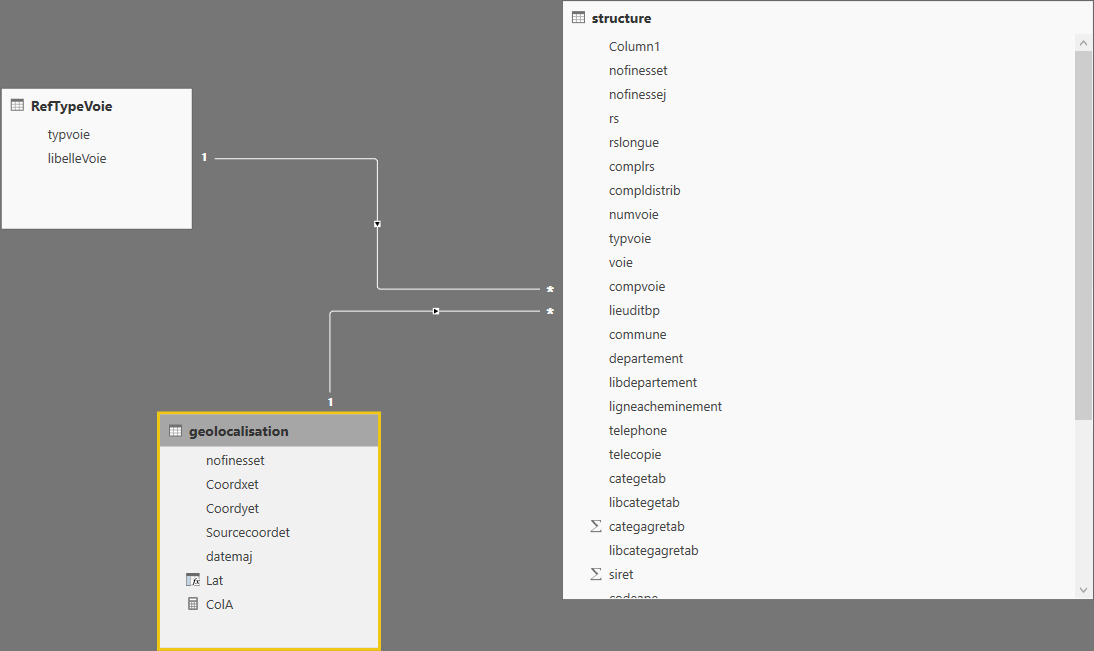
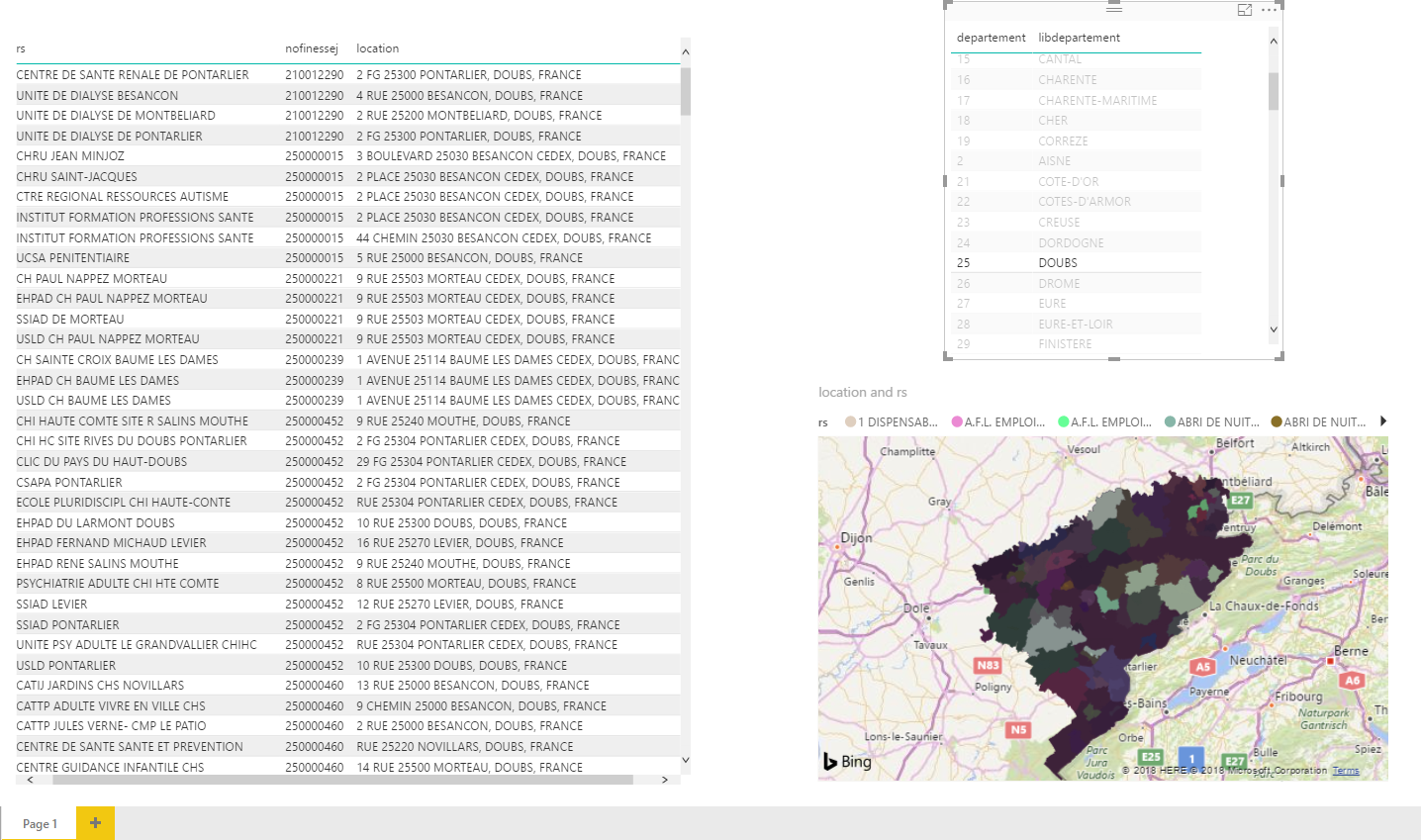
J’ai du répondre à une question simple de prime abord, comment mettre un jour un référentiel, non prévu pour être versionné, et ayant pu évoluer de manière différente sur chacun des différents sites de manière indépendante.
Après quelques recherches, le principal mot clé qui pouvait revenir était : MERGE
Un merge pour un développeur, c’est quelque chose de connu et ce n’est pas souvent envisager comme quelque chose de simple et de généralisable.
En théorie si, mais en pratique, c’est souvent durant cette étape que la livraison de son code prend un retard inattendu.
Alors avant d’envisager une telle pratique quand on utilise traditionnellement le SQL pour faire de simple CRUD … on cherche du simple … on envisage de se mettre au PL …. voir de faire une mini application faisant ce que l’on veut.
Et pourtant, le merge cela peut aussi être simple dans certain cas et cela peut rapidement être mis en place.
Comme dit en introduction, mon contexte était le suivant :
– Mise à jour de référentiel
– Pas d’assurance sur l’état du référentiel avant travaux
– Pas nécessairement le temps de s’assurer de la cohérence des données pour chacun des sites.
A priori, il existe plusieurs techniques, plus ou moins simple pouvant arriver à ce résultat.
Dans mon cas, il fallait que le génération du script se fasse dans un temps relativement court … et en ne demandant pas de devenir DBA au passage.
Le processus choisit pour l’actualisation de la table fut le suivant :
– Mise en place d’une date de fin pour l’ensemble des champs du référentiel utilisé en production (assurance de conserver les champs pour les données déjà saisies).
– Injection de la nouvelle table de référentiel
– merge proprement dit entre l’ancienne table et la nouvelle afin d’actualiser les champs utiles, quelques soit l’état de la table initialement.
En SQL, cela donne cela :
-- Généralisation de la date de fin à l'ensemble des occurrences de la table
update SOC_TYPE_DOMICILE set datefin= '01/11/14';
-- Injection de la table référentiel nouvelle version
CREATE TABLE "SOC_TYPE_DOMICILE_REF"
( "CODE" VARCHAR2(10 BYTE),
"CODEREGROUPEMENT" VARCHAR2(10 BYTE),
"DATEDEBUT" DATE,
"DATEFIN" DATE,
"LIBELLE" VARCHAR2(100 BYTE),
"RANGAFFICHAGE" NUMBER(3,0),
"ANCIENCODECSD" VARCHAR2(10 BYTE),
"CODEREGROUPEMENTTYPE" VARCHAR2(10 BYTE),
"ID_LIBELLE" NUMBER(7,0)
);
Insert into SOC_TYPE_DOMICILE_REF (CODE,CODEREGROUPEMENT,DATEDEBUT,DATEFIN,LIBELLE,RANGAFFICHAGE,ANCIENCODECSD,CODEREGROUPEMENTTYPE,ID_LIBELLE) values ('SIFO','SIT_LOC',to_date('01/01/07','DD/MM/RR'),to_date('01/11/14','DD/MM/RR'),'Sans information','1','0',null,null);
Insert into SOC_TYPE_DOMICILE_REF (CODE,CODEREGROUPEMENT,DATEDEBUT,DATEFIN,LIBELLE,RANGAFFICHAGE,ANCIENCODECSD,CODEREGROUPEMENTTYPE,ID_LIBELLE) values ('HEBST','SIT_LOC',to_date('01/01/07','DD/MM/RR'),to_date('01/11/14','DD/MM/RR'),'Hébergement stable','2','2',null,null);
Insert into SOC_TYPE_DOMICILE_REF (CODE,CODEREGROUPEMENT,DATEDEBUT,DATEFIN,LIBELLE,RANGAFFICHAGE,ANCIENCODECSD,CODEREGROUPEMENTTYPE,ID_LIBELLE) values ('HEBPR','SIT_LOC',to_date('01/01/07','DD/MM/RR'),to_date('01/11/14','DD/MM/RR'),'Hébergement précaire ou de durée incertaine','3','A',null,null);
Insert into SOC_TYPE_DOMICILE_REF (CODE,CODEREGROUPEMENT,DATEDEBUT,DATEFIN,LIBELLE,RANGAFFICHAGE,ANCIENCODECSD,CODEREGROUPEMENTTYPE,ID_LIBELLE) values ('HOP','SIT_LOC',to_date('01/01/07','DD/MM/RR'),to_date('01/11/14','DD/MM/RR'),'Hôpital sans perspective de logement à la sortie','4','B',null,null);
Insert into SOC_TYPE_DOMICILE_REF (CODE,CODEREGROUPEMENT,DATEDEBUT,DATEFIN,LIBELLE,RANGAFFICHAGE,ANCIENCODECSD,CODEREGROUPEMENTTYPE,ID_LIBELLE) values ('SAB','SIT_LOC',to_date('01/01/07','DD/MM/RR'),to_date('01/11/14','DD/MM/RR'),'Sans abri, absence totale d hébergement','5','1',null,null);
-- Merge
-- deux cas : la ligne existe : dans ce cas on modifie le libellé pour qu'il corresponde exactement avec le résultat attendu (les valeurs, même modifiées, ne changent pas de sens)
-- La ligne n'existe pas, on l'insère
MERGE INTO SOC_TYPE_DOMICILE S
USING SOC_TYPE_DOMICILE_REF R
ON ( S.CODE = R.CODE )
WHEN matched
THEN UPDATE SET S.DATEFIN = null, S.LIBELLE = R.LIBELLE, S.RANGAFFICHAGE = R.RANGAFFICHAGE, S.ANCIENCODECSD = R.ANCIENCODECSD
WHEN not MATCHED
THEN INSERT (CODE,CODEREGROUPEMENT,DATEDEBUT,DATEFIN,LIBELLE,RANGAFFICHAGE,ANCIENCODECSD,CODEREGROUPEMENTTYPE,ID_LIBELLE)
VALUES (R.CODE,R.CODEREGROUPEMENT,R.DATEDEBUT,R.DATEFIN,R.LIBELLE,R.RANGAFFICHAGE,R.ANCIENCODECSD,R.CODEREGROUPEMENTTYPE,R.ID_LIBELLE);
-- et c'est fini ...